
Vibe Training a Chess Puzzle Model Like Deepmind
Supervised Pre-Training

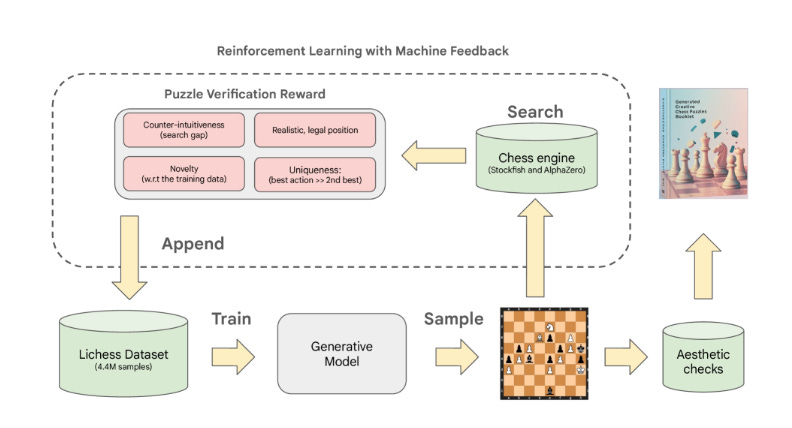
On the 27th of October, DeepMind, the creators of AlphaZero, shared an interesting paper (https://arxiv.org/html/2510.23881v1). They had succeeded in training a model that could compose rather creative chess puzzles.
If you want a taste, watch IM Levy Rozman present some of them here:
Levy presents the training as a miracle from our AI overlords, but I got interested to understand how they did it, and whether I could replicate it on a smaller scale.
* Before we go any further, just a warning: I’m not an AI scientist, just a hobbyist trying to understand what is going on with assistance from Claude for coding.
Supervised Pre-Training
The first step, before we can go on to creating puzzles, is to teach the model how to make legal chess positions that imitate chess puzzles.
We do this, as the DeepMind team did, by using training examples from the Lichess puzzle database. I have chosen 50,000 examples from the database, while the DeepMind team used the full 4M+ puzzles.
The 64 squares are then transformed into tokens that we train the model to predict what is on each square in reference to real Lichess puzzles. First, I tried a light setup where I used something called an LSTM model or Long Short-Term Memory.
The DeepMind team used a much more powerful Transformer model with 200 million parameters trained on their full 4.4 million puzzle dataset, but running that would require expensive GPU clusters that I simply don’t have access to on my Replit CPU setup.
The LSTM model has around ~230K parameters, which is like comparing in size my is 0.1% the size of the DeepMind model, but it should hopefully be enough to see if the core ideas from the paper actually work on a budget.
If I were to train you, what piece would you predict was going to be placed on h5 in this diagram? (answer:1)

We then split the training data into batches and feed these batches to the model and ask for predictions. After each epoch, the model is updated based on the results of the batches it has trained on. With each new step or epoch, we slowly adjust these parameters until we can construct what looks like tactical positions.
Let’s take a look at my results trying to do this.
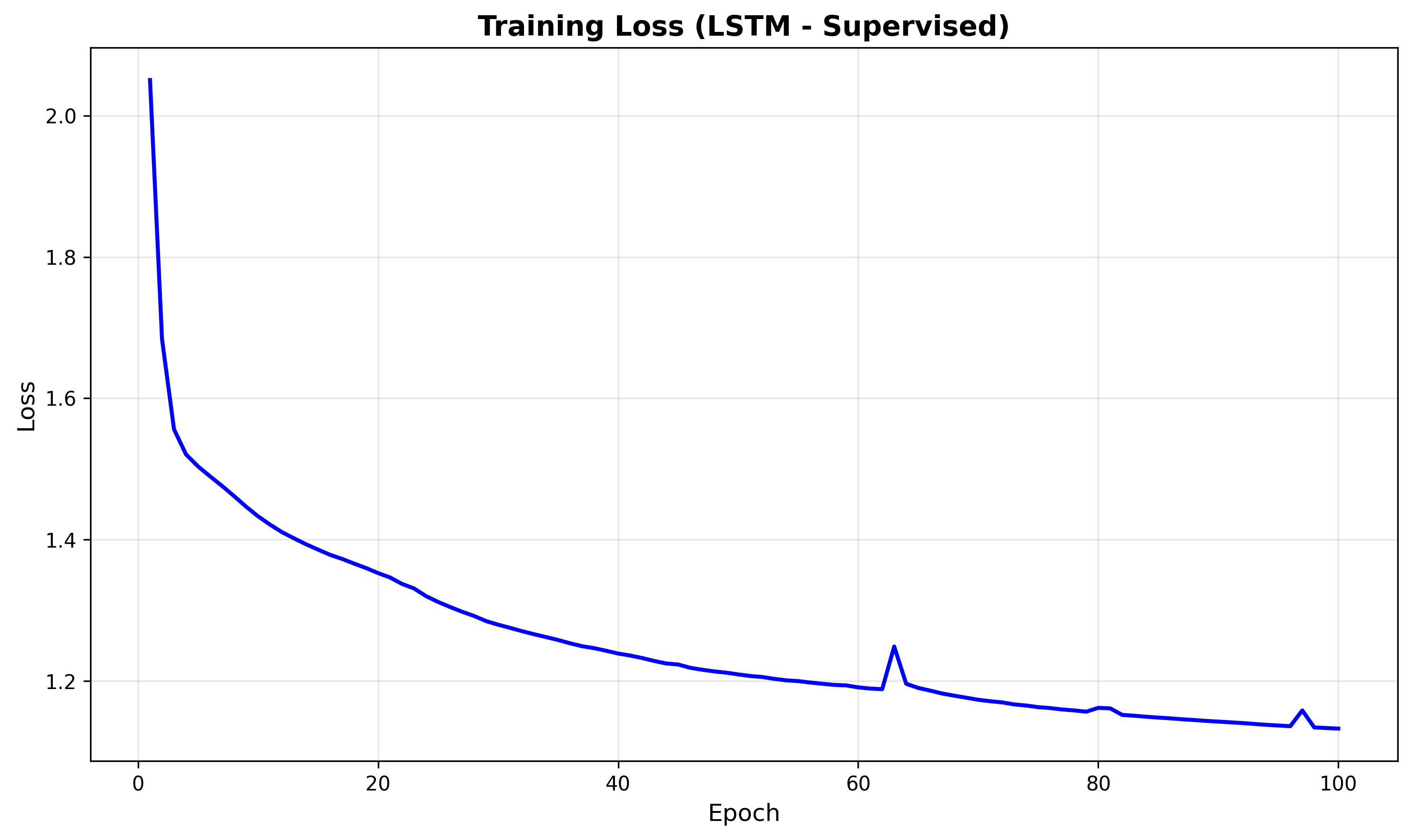
Here we see that with each new epoch we slowly improve our accuracy until we reach a plateau around epochs 80-100, where we get diminishing returns on each new update of our prediction parameters.
While this may not explain much to you, it might be better to look at actual output of model predictions at different stages of the training. These positions are just “what the model thinks a board looks like right now,” not the model’s per-square predictions for some particular training FEN.
Epoch 1
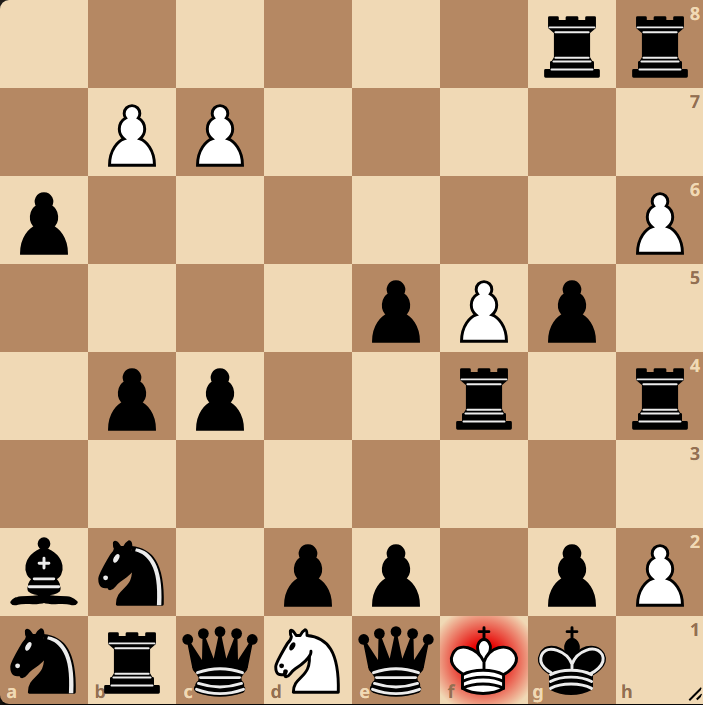
Epoch 5

Epoch 10
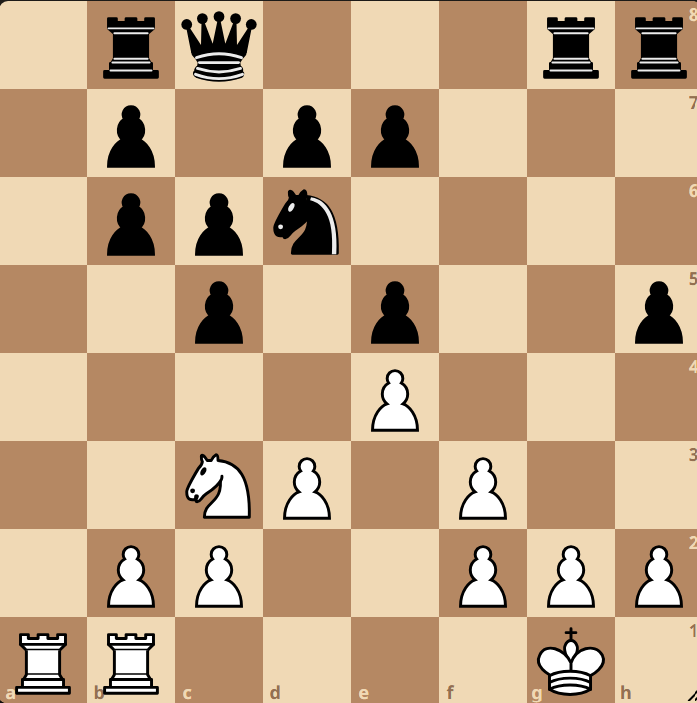
Epoch 50

Epoch 100
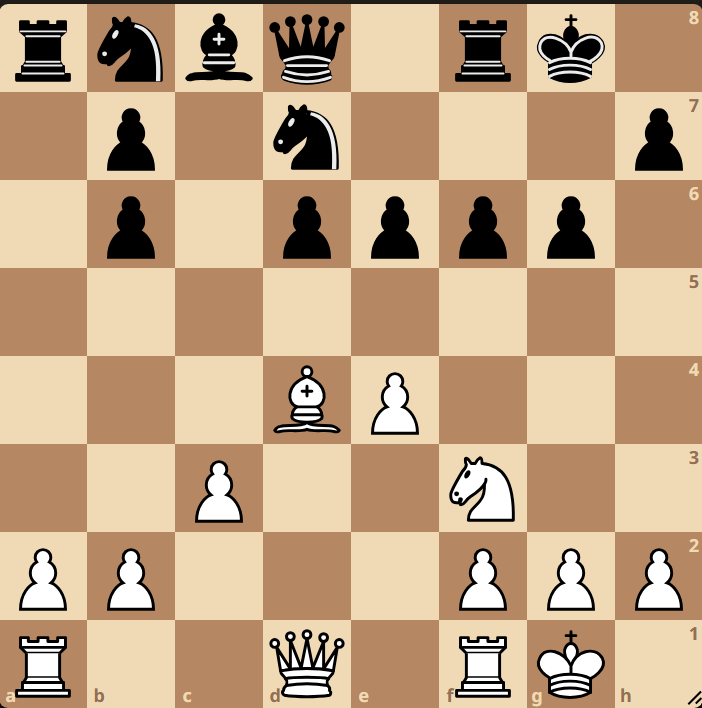
Epoch 125
As you can see the positions moves from random towards more familiar chess patterns, but if you are sharp you might spot a mistake even after 125 epochs of training! To my understanding the LSTM model “reads” the chess positions as a string (a1, b1, c1…), while a transformer model would be better for 2D patterns.
Therefore, I went a step further and build a transformer model, which is larger and takes more resources to train. I used Google Colab, where I could get access to free online CPU/GPU power for training. For comparison the transformer model I trained has ~2M parameters vs the ~230K parameters of the LSTM model.
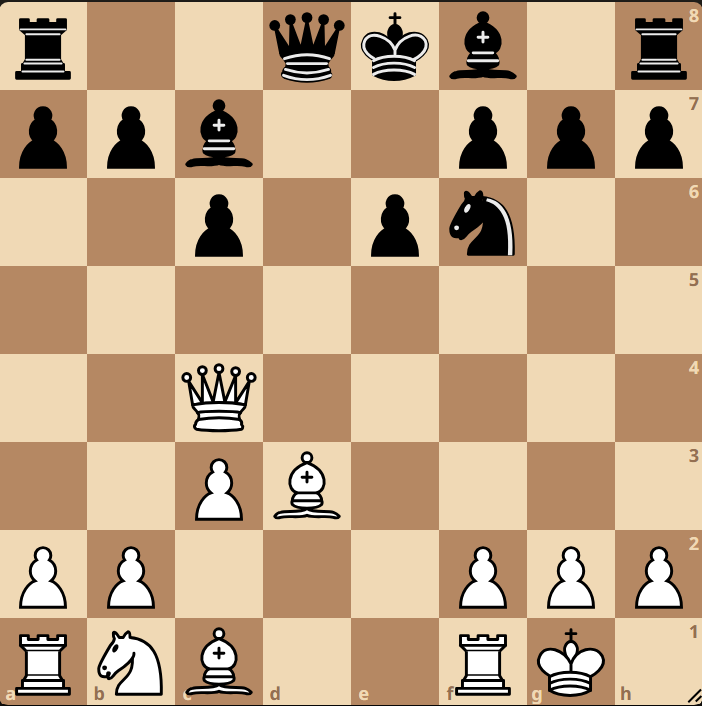
Here is the test output after 150 epochs of training with the tranformer model:
As you see we now have, what feels like a very normal position, that could originate from normal play.
As a result of this training, we now have a model that has learned to generate legal chess positions that resemble the tactical puzzles it was trained on. The model has not yet learned what a real tactic is, but just what likely is a tactical puzzle based on the training data.
The next step is to create interesting or counter-intuitive puzzles. This is where reinforcement learning comes in, which I’ll cover in the next post.
Right now, I’m searching for counter-intuitive and creative puzzles in the Lichess puzzle data, which I plan to use as examples in the reinforcement learning.
If you want to get the next post and see if I manage to generate an actual AI-chess-puzzle, then hit the subscribe button.
If you have any ideas or comments, please let me know.
/Martin
A Queen (so Qf7! with the idea of Qg8# and the Knight on f8 has no squares)
If I'm being completely honest, Epoch One looks like it could be from any scholastic tournament's lowest section.
'assistance from Claude for coding, why Claude?