
Part II of Mapping Checkmate Patterns with a 27-Dimensional Fingerprint

Last week, I attempted to identify and organize checkmate patterns by applying a clustering algorithm, focusing specifically on the 3×3 squares surrounding the checkmated king.

The method looked promising, but some sharp readers noticed a slight flaw in the approach—something I also had questioned. The flaw was that when the attacking sum and occupancy of each square were calculated I used this method for scoring:
1=Pawn, 2=Knight, 3=Bishop, 4=Rook, 5=Queen, 6=King.
"""
if piece is None:
return 0If a square was attacked by multiple pieces, their scores were combined—meaning a pawn and a knight attacking the same square would be treated as equivalent to a bishop.
Another issue with this approach was that the clustering algorithm calculated distances based on numerical values, causing a queen to have significantly more weight than a pawn, which was not the intended effect.
Hamming distance
What I needed was a way to input information about the positions without using numbers initially, since the goal is not to favor some kind of positions over others, just to find similar patterns of checkmate.
After some tries and searching I asked ChatGPT to make a model that used P for pawn, K for Knight, B for Bishop, etc., and make the whole string into letters and dots for empty squares.
ChatGPT suggested that I use hamming distance instead. Here is an explanation from Wikipedia:
In information theory, the Hamming distance between two strings or vectors of equal length is the number of positions at which the corresponding symbols are different. In other words, it measures the minimum number of substitutions required to change one string into the other, or equivalently, the minimum number of errors that could have transformed one string into the other. In a more general context, the Hamming distance is one of several string metrics for measuring the edit distance between two sequences. It is named after the American mathematician Richard Hamming.
Examples
The symbols may be letters, bits, or decimal digits, among other possibilities. For example, the Hamming distance between:
"karolin" and "kathrin" is 3.
"karolin" and "kerstin" is 3.
"kathrin" and "kerstin" is 4.
0000 and 1111 is 4.
2173896 and 2233796 is 3.1
This was perfect and just what I needed. Each checkmate position could now be turned into a string without the piece values distorting the clusters:
.K....K...XXXXXp....kQ...XXXXX.Q...p....XXXXX
.K........XXXXX.K...kR...XXXXX.K....R...XXXXX
XXXXX.P...p....XXXXXkR....R...XXXXXXXXXXXXXXX
These strings can now be compared without numerical values distorting the process.
However, I discovered a new problem!
Many patterns was mirrored patterns or rotated 0°, 90°, 180°, and 270°. If I were to collect these in a book I would have to cluster these patterns together as well!
Dihedral transformations of the 3×3 matrix
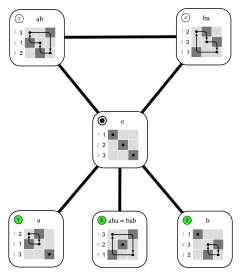

They say chess helps train visualization, but I had to put in some effort to grasp the concept of dihedral transformations. By first generating all rotated and mirrored versions of the checkmate string and then selecting the lexicographically smallest one, I was able to consistently group mirrored patterns together!

As a result, I now got result where these two patterns clustered together. The pattern here is a Bishop and a pawn blocking the escape squares so the Queen can deliver the checkmate from the corner square in the matrix.
Here is another example with the Knight and Bishop combo.

Finally, some patterns are very similar like this King and Queen mate.

Interestingly, this new approach led to a significant increase in the number of clusters—410 in total. The map below highlights only the clusters containing at least 10 puzzles, derived from a database of 10,000 puzzles. Might also be because I increased the puzzle database. I decided to set the hamming distance to ~0 to get identical patterns, if I set it to 5 it would allow for larger clusters of somewhat similar patterns.

Checkmate Pattern Test
I've compiled a sheet with nine puzzles from Cluster 1, allowing you to test how quickly you can recognize the checkmate pattern. The puzzles are arranged in order of increasing difficulty, starting with the easiest.
The next step is to create a book featuring the 100 most common checkmate patterns (900 puzzles), selected from the largest clusters identified in the analysis. To maintain a challenge, the puzzles will be selected from the hardest examples within each pattern cluster, since once a pattern is recognized, the difficulty naturally decreases. This approach ensures that readers still need to think critically while reinforcing their ability to spot recurring checkmate motifs.
Please leave a comment if you have feedback or a good title for the book!
/Martin
When you get to tensors my heart will explode 😉
Well done.
HI Martin, your work has been amazing, I am sure you can write a thesis on Chess. As per the title is concerned, "Recurring Checkmates" would be short and sweet. attracting both the beginner and advanced. we already have books on the types of checkmates but your focus is on what is most repeating with the graph that you have shared.